Oblačná lokalizace s MemSource
Minule jsme tvořili uživatelský manuál a dnes bychom ho rádi přeložili do jiného jazyka. Ale jak na to? Datlovat ručně větu po větě je už v dnešní době pasé, neboť existuje spousta šikovných CAT nástrojů, které dokáží práci výrazně zjednodušit.
Lokalizace softwaru kromě překladu dokumentace znamená i jazykový překlad a přizpůsobení samotné aplikace. Nejčastěji jsou texty uloženy jako tzv. string resources, se kterými umí zacházet většina vývojových prostředí. Taky ale mohou být součástí layoutu formulářů nebo nacpané do knihoven, záleží na konkrétním produktu.
CAT a jiná zvířátka
Nástrojů z kategorie CAT (computer-aided translation, počítačem podporovaný překlad) existuje nespočet a v nejrůznějším provedení - samostatné aplikace, klient-server řešení, pluginy, makra do Wordu, komerční i open source. Zpravidla disponují překladovou pamětí (translation memory, TM) a terminologickou databází (terminology database, TB); díky tomu umí automaticky doplňovat již dříve přeložené segmenty a udržovat konzistentní názvosloví. Nutností je podpora nejrůznějších formátů textu, které chceme překládat.
Některé nástroje také umí text před-přeložit s využitím služeb strojového překladu (Google Translate, Microsoft Translator apod). Pokud je strojový překlad dostatečně kvalitní, překladateli stačí jen projít text a opravit případné nesrovnalosti (ideální případ).
Napěchovat všechny funkce do jednoho paklu ale něco stojí, a tak tradiční komplexní řešení á la Trados začínají připomínat dýchavičného slona. Hledáme něco jednoduššího.

V oblaku
Jedním z aktuálních trendů je cloud translation, tedy překlad textu a jeho organizace s pomocí webových služeb. (Prosím nezaměňovat s crowd translation, označením pro hromadné zajišťování překladatelů na dálku přes web.)
Tyto cloudové služby zpravidla nabízejí to samé co tradiční desktopové nástroje - překladový editor, import/export překládaných textů, správu TM/TB - a navíc zajišťují kompletní workflow překladu. To znamená zadání zakázky do systému, přiřazení překladateli, před-přeložení, samotný překlad překladatelem, korekturu, analýzu, odeslání výsledku zákazníkovi, fakturaci a uzavření zakázky. Všechna data jsou uchována na serveru, TM/TB i samotné překladové texty tak mohou být sdíleny více překladateli.
Po menší rešerši jsem objevil několik variant:
- Pouze desktop: Klasický all-in-one editor, který se navíc synchronizuje s cloudem. Příklad: TextUnited.
- Pouze web: Správa projektů i překladový editor skrze webové rozhraní. Příklad: XTM Cloud, WordBee.
- Desktop + web: Kombinace desktopového editoru a webového rozhraní pro správu projektů. Příklad: MemSource.
Pěkné shrnutí toho, co přináší cloud translation, lze najít například v tomto článku. Co je však v každém případě pro efektivní překládání důležité?
Je to sakra dobrý editor. Tedy rychlý, robustní, přehledný, s potřebnými klávesovými zkratkami a bezchybnou prací se segmenty a překladovou pamětí. Takový, co rychle hledá, nebojí se velkých souborů, umí pracovat i offline a nemrší formát editovaných dokumentů. To znamená desktopová aplikace, aspoň prozatím.
Lehký úvod do MemSource
Na téhle myšlence je postavený MemSource, který původně vznikl jako výzkumný projekt na Karlově univerzitě. Samotný editor překládaných textů zůstává na desktopu jako odlehčený klient, zatímco celá komplexní workflow logika je přesunuta na server.
Multiplatformní editor a osobní účet pro občasné použití je zdarma, ostatní účty pro freelancery, týmy a větší firmy vyžadují měsíční předplatné. Eventulně lze místo veřejného cloudu zakoupit a provozovat vlastní firemní MemSource server.
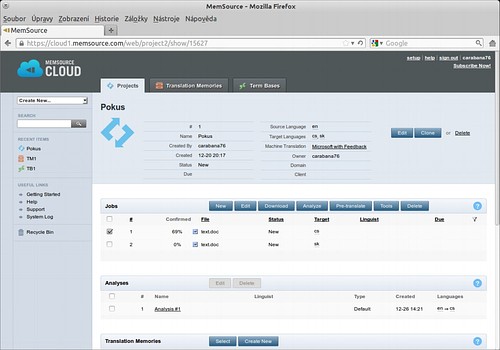
Typický workflow je následující:
- Správce vytvoří na serveru projekt, naimportuje texty pro překlad a stáhne dvojjazyčné překladové soubory XMLIFF (prázdné nebo již před-přeložené), které zašle vybranému překladateli. Případně může větší soubory rozdělit a poslat více lidem.
- Překladatel přeloží soubory a přímo z editoru je odešle zpět na server. TM/TB jsou synchronizované automaticky.
- Správce zkontroluje a vyexportuje překlad.
Webové rozhraní i editor jsem si vyzkoušel na krátkém dokumentu (*.doc) a archivu s lokalizačními řetězci aplikace napsané v Javě (*.properties). Odborné zhodnocení raději přenechám profesionálovi, podělím se však o několik praktických zkušeností, které jsem během používání získal.
Webové rozhraní mělo zpočátku problémy s firemní proxy, které se ale díky skvělému suportu podařilo rychle vyřešit. Trochu zamrzí chybějící čeština, ale v této branži se zřejmě předpokládá, že všichni umí anglicky. Naopak mě potěšilo, že lze naimportovat více souborů naráz jako archiv s adresářovou strukturou, která i ve výsledném překladu zůstane zachována.
Větší detektivka byla s editorem. Nejprve jsem nemohl najít odkaz ke stažení, ke kterému vede cesta skrze nepříliš přehlednou wiki, pak jsem neúspěšně zápasil s instalací a zprovozněním v Ubuntu 12.10 (poslední podporovaná verze je 12.04) a nakonec raději použil verzi pro Windows. Zde již fungovalo vše bez problémů, jen mě překvapilo, že po zadání přihlašovacích údajů do cloudu se aplikace musela restartovat.
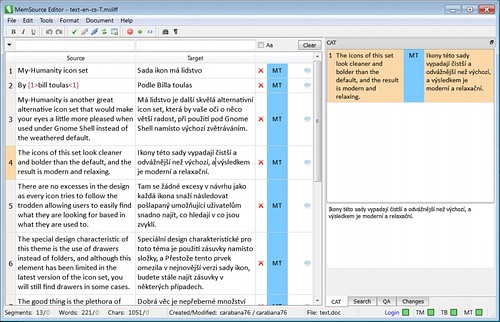
Samotné překládání v editoru je rychlé a pohodlné. Věty jsou automaticky rozděleny na segmenty, přičemž každý přeložený segment je potřeba potvrdit. Při potvrzení segmentu se skočí na další a předvyplní se se s pomocí TM nebo strojového překladu, pokud je prázdný. V samostatné kolonce je uveden zdroj, případně kvalita překladu (100%, 101%, TM, ...). Ikonky ve stavové liště signalizují připojení k serveru.
Pro kontrolu pravopisu se oplatí vyexportovat text jako dvojjazyčný DOCX soubor, provést kontrolu ve Wordu a naimportovat zpět. Vestavěný spellchecker toho moc neumí a pro češtinu se mi jej vůbec nepodařilo nainstalovat. Naštěstí vývoj editoru probíhá poměrně rychle a výborně reaguje na podněty od uživatelů. Doufám tedy, že i tyto problémy budou brzy vyřešeny.
Ve výsledku se jedná o zajímavý a užitečný produkt, který ukazuje, kam se budou CAT nástroje v příštích letech ubírat. Proto budu rád, když se v komentářích podělíte o vlastní zkušenosti s tímto typem služeb.